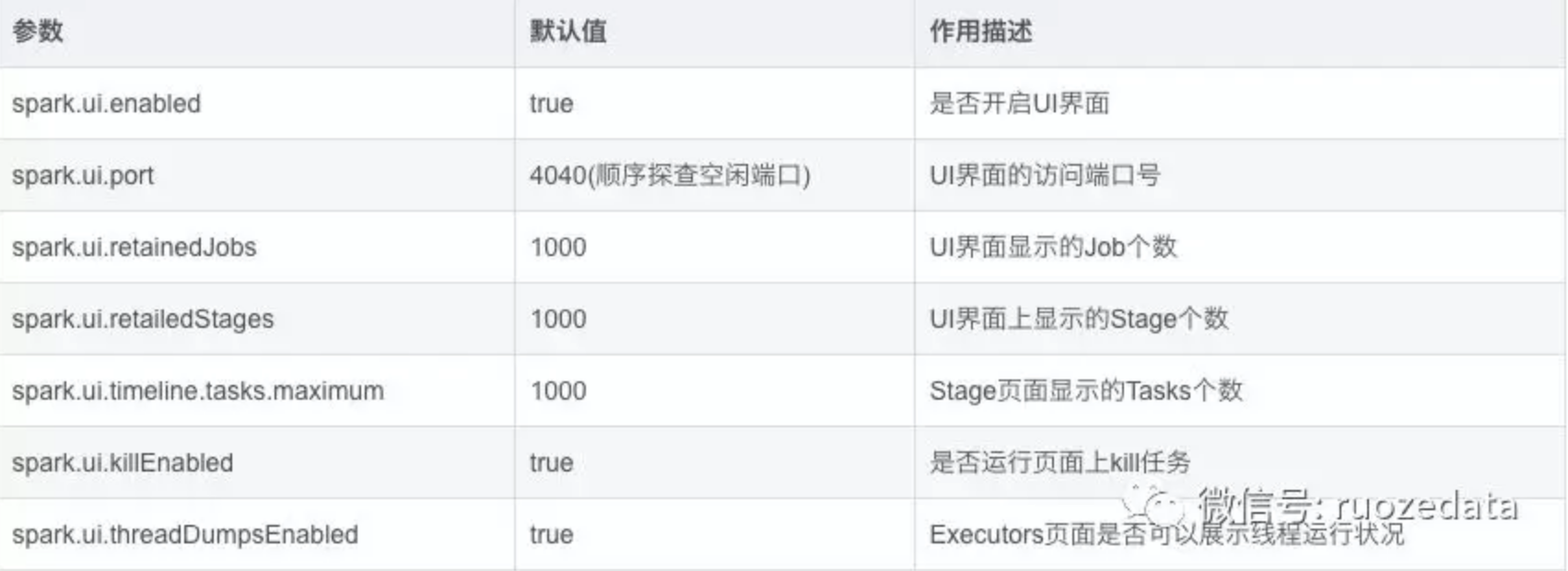
当Spark程序在运行时,会提供一个Web页面查看Application运行状态信息。是否开启UI界面由参数spark.ui.enabled(默认为true)来确定。下面列出Spark UI一些相关配置参数,默认值,以及其作用。
本文接下来分成两个部分,第一部分基于Spark-1.6.0的源码,结合第二部分的图片内容来描述UI界面在Spark中的实现方式。第二部分以实例展示Spark UI界面显示的内容。
Spark UI界面实现方式
UI组件结构
这部分先讲UI界面的实现方式,UI界面的实例在本文最后一部分。如果对这部分中的某些概念不清楚,那么最好先把第二部分了解一下。
从下面UI界面的实例可以看出,不同的内容以Tab的形式展现在界面上,对应每一个Tab在下方显示具体内容。基本上Spark UI界面也是按这个层次关系实现的。
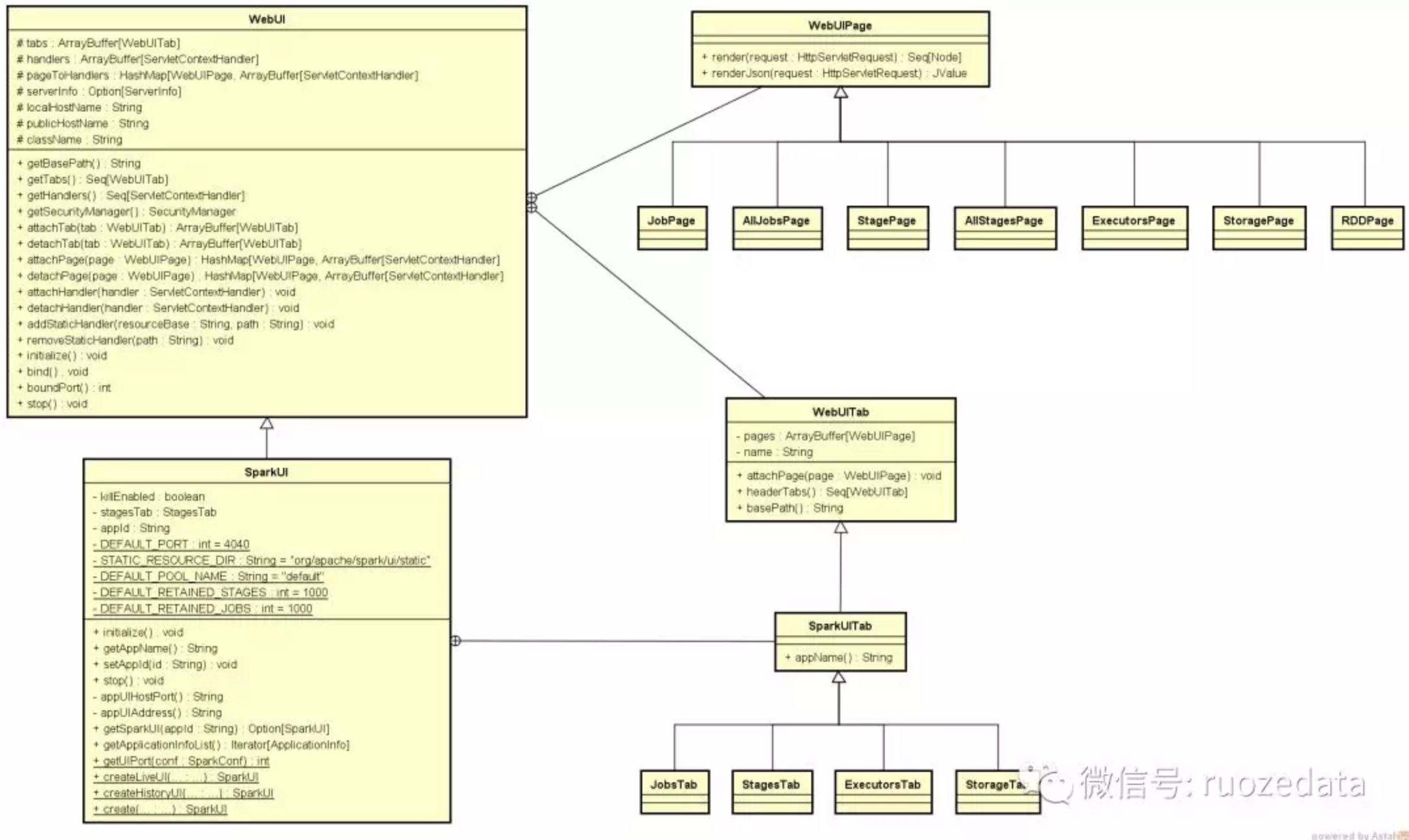
以SparkUI类为容器,各个Tab,如JobsTab, StagesTab, ExecutorsTab等镶嵌在SparkUI上,对应各个Tab,有页面内容实现类JobPage, StagePage, ExecutorsPage等页面。这些类的继承和包含关系如下图所示:
初始化过程
从上面可以看出,SparkUI类型的对象是UI界面的根对象,它是在SparkContext类中构造出来的。
1 | private var _ui: Option[SparkUI] = None //定义 |
上面这段代码中可以看到SparkUI对象的生成过程,结合上面的类结构图,可以看到bind方法继承自WebUI类,进入WebUI类中
1 | protected val handlers = ArrayBuffer[ServletContextHandler]() // 这个对象在下面bind方法中会使用到。 |
上面代码中handlers对象维持了WebUIPage和Jetty之间的关系,org.eclipse.jetty.servlet.ServletContextHandler是标准jetty容器的handler。而对象pageToHandlers维持了WebUIPage到ServletContextHandler的对应关系。
各Tab页以及该页内容的实现,基本上大同小异。接下来以AllJobsPage页面为例仔细梳理页面展示的过程。
SparkUI中Tab的绑定
从上面的类结构图中看到WebUIPage提供了两个重要的方法,render和renderJson用于相应页面请求,在WebUIPage的实现类中,具体实现了这两个方法。在SparkContext中构造出SparkUI的实例后,会执行SparkUI#initialize方法进行初始化。如下面代码中,调用SparkUI从WebUI继承的attacheTab方法,将各Tab页面绑定到UI上。
1 | def initialize() { |
页面内容绑定到Tab
在上一节中,JobsTab标签绑定到SparkUI上之后,在JobsTab上绑定了AllJobsPage和JobPage类。AllJobsPage页面即访问SparkUI页面时列举出所有Job的那个页面,JobPage页面则是点击单个Job时跳转的页面。通过调用JobsTab从WebUITab继承的attachPage方法与JobsTab进行绑定。
1 | private[ui] class JobsTab(parent: SparkUI) extends SparkUITab(parent, "jobs") { |
页面内容的展示
知道了AllJobsPage页面如何绑定到SparkUI界面后,接下来分析这个页面的内容是如何显示的。进入AllJobsPage类,主要观察render方法。在页面展示上Spark直接利用了Scala对html/xml的语法支持,将页面的Html代码嵌入Scala程序中。具体的页面生成过程可以查看下面源码中的注释。这里可以结合第二部分的实例进行查看。
1 | def render(request: HttpServletRequest): Seq[Node] = { |
接下来以activeJobsTable代码为例分析Jobs信息展示表格的生成。这里主要的方法是makeRow,接收的是上面代码中的activeJobs, completedJobs, failedJobs。这三个对象都是包含在JobProgressListener对象中的,在JobProgressListener中的定义如下:
1 | // 这三个对象用于存储数据的主要是JobUIData类型, |
将上面三个对象传入到下面这段代码中,继续执行。
1 | private def jobsTable(jobs: Seq[JobUIData]): Seq[Node] = { |
从上面这些代码中可以看到,Job页面显示的所有数据,都是从JobProgressListener对象中获得的。SparkUI可以理解成一个JobProgressListener对象的消费者,页面上显示的内容都是JobProgressListener内在的展现。
Spark UI界面实例
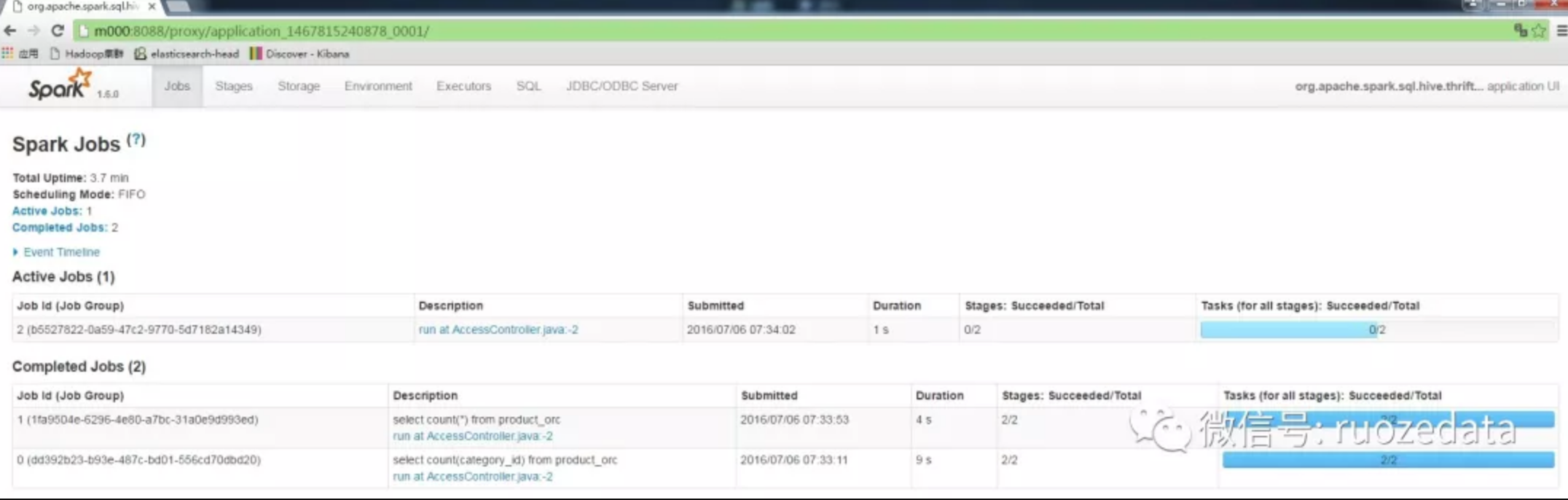
默认情况下,当一个Spark Application运行起来后,可以通过访问hostname:4040端口来访问UI界面。hostname是提交任务的Spark客户端ip地址,端口号由参数spark.ui.port(默认值4040,如果被占用则顺序往后探查)来确定。由于启动一个Application就会生成一个对应的UI界面,所以如果启动时默认的4040端口号被占用,则尝试4041端口,如果还是被占用则尝试4042,一直找到一个可用端口号为止。
下面启动一个Spark ThriftServer服务,并用beeline命令连接该服务,提交sql语句运行。则ThriftServer对应一个Application,每个sql语句对应一个Job,按照Job的逻辑划分Stage和Task。
Jobs页面
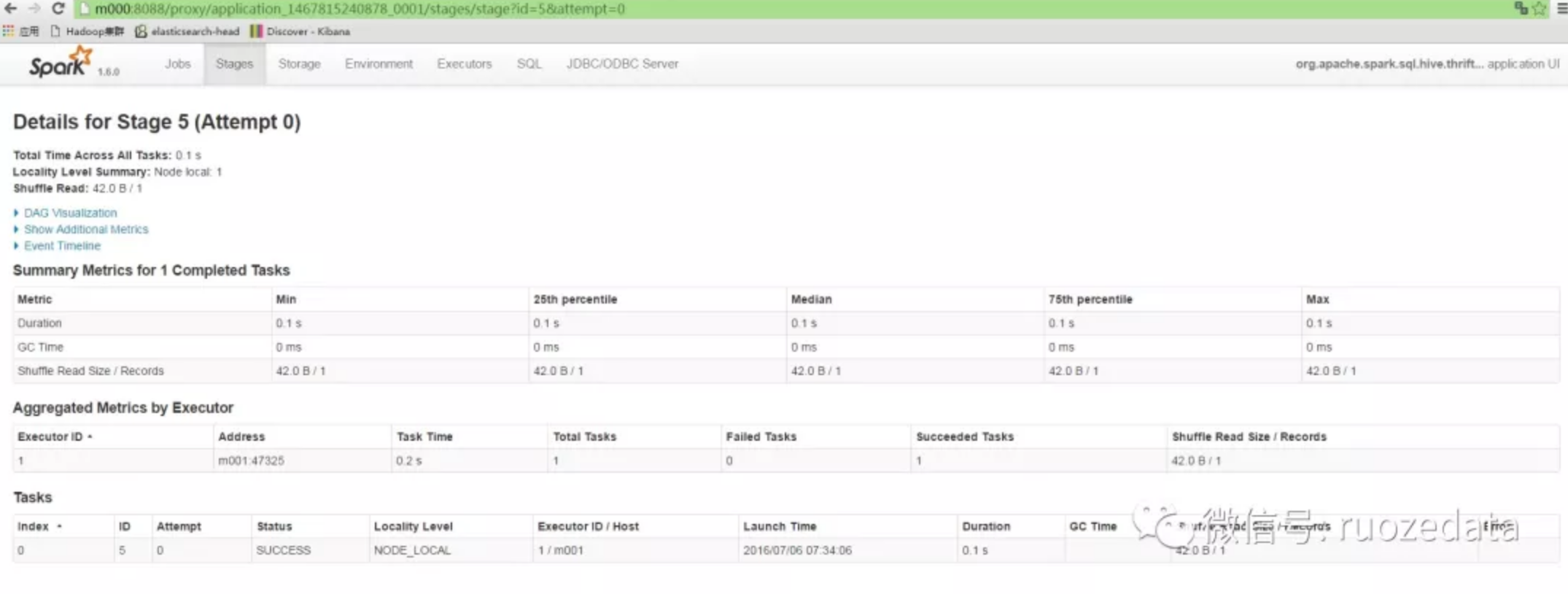
连接上该端口后,显示的就是上面的页面,也是Job的主页面。这里会显示所有Active,Completed, Cancled以及Failed状态的Job。默认情况下总共显示1000条Job信息,这个数值由参数spark.ui.retainedJobs(默认值1000)来确定。
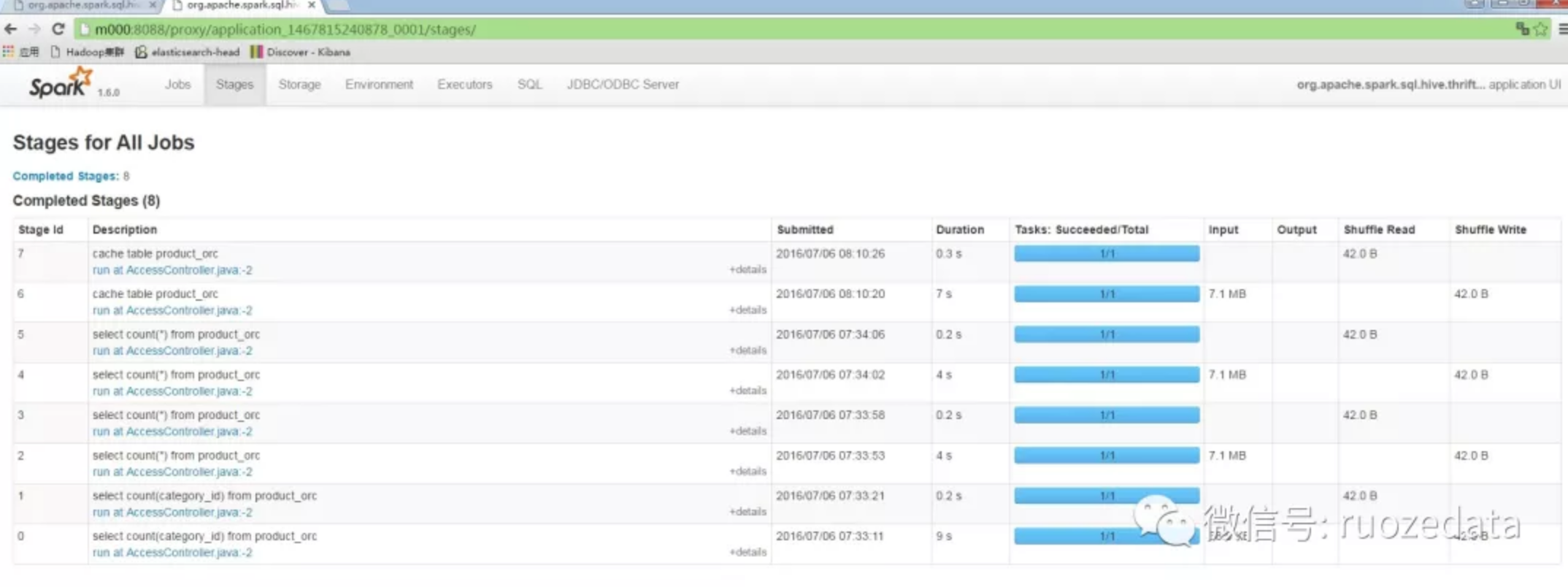
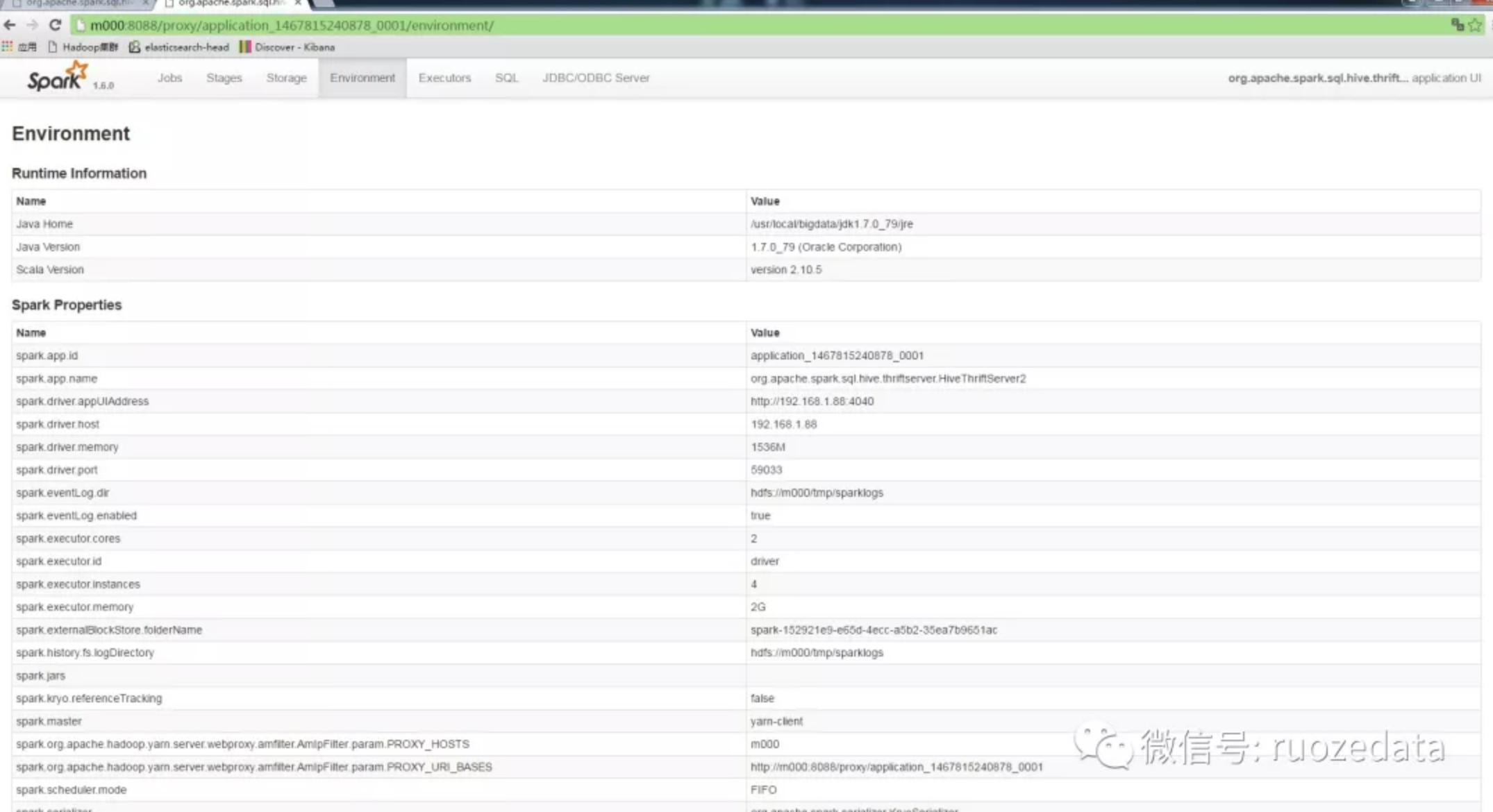
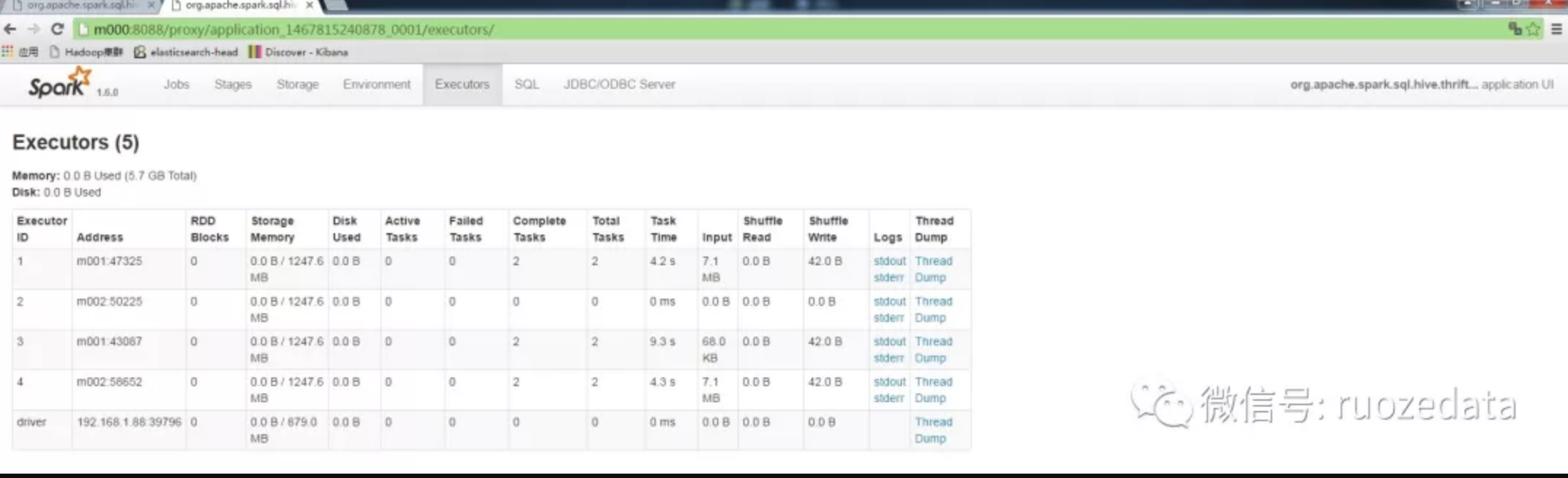
从上面还看到,除了Jobs选项卡之外,还可显示Stages, Storage, Enviroment, Executors, SQL以及JDBC/ODBC Server选项卡。分别如下图所示。
Stages页面
Storage页面

Enviroment页面
Executors页面
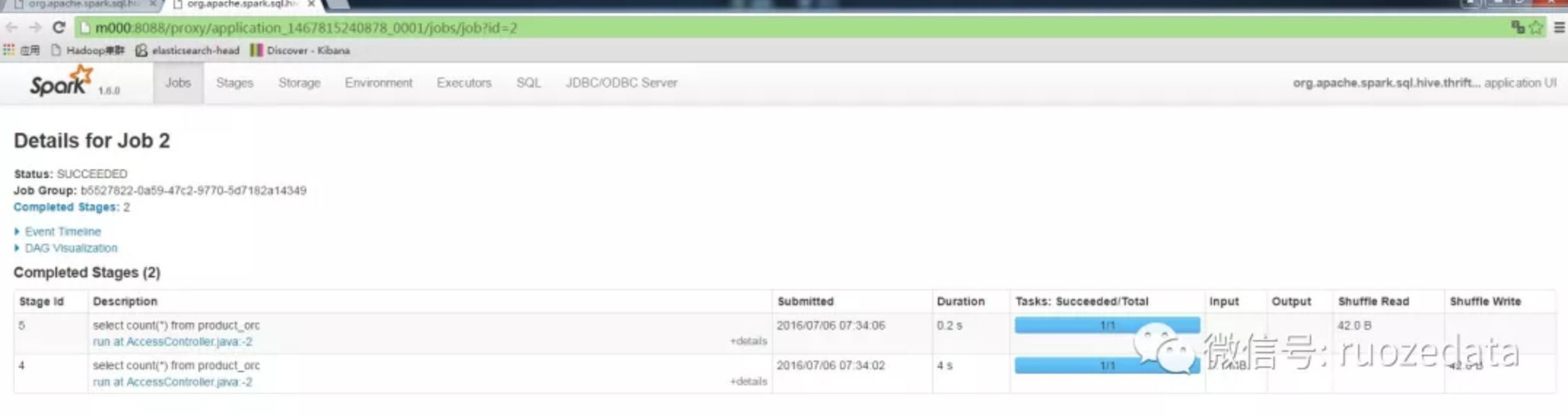
单个Job包含的Stages页面
Task页面